A Delta Lake table representing metadata about content posts from users has the following schema:
user_id LONG, post_text STRING, post_id STRING, longitude FLOAT, latitude FLOAT, post_time TIMESTAMP, date DATE
This table is partitioned by the date column. A query is run with the following filter:
longitude < 20 and longitude > -20
Which statement describes how data will be filtered?
In order to facilitate near real-time workloads, a data engineer is creating a helper function to leverage the schema detection and evolution functionality of Databricks Auto Loader. The desired function will automatically detect the schema of the source directly, incrementally process JSON files as they arrive in a source directory, and automatically evolve the schema of the table when new fields are detected.
The function is displayed below with a blank:

Which response correctly fills in the blank to meet the specified requirements?

The data engineer team is configuring environment for development testing, and production before beginning migration on a new data pipeline. The team requires extensive testing on both the code and data resulting from code execution, and the team want to develop and test against similar production data as possible.
A junior data engineer suggests that production data can be mounted to the development testing environments, allowing pre production code to execute against production data. Because all users have
Admin privileges in the development environment, the junior data engineer has offered to configure permissions and mount this data for the team.
Which statement captures best practices for this situation?
Where in the Spark UI can one diagnose a performance problem induced by not leveraging predicate push-down?
A data engineer needs to install the PyYAML Python package within an air-gapped Databricks environment . The workspace has no direct internet access to PyPI. The engineer has downloaded the .whl file locally and wants it available automatically on all new clusters.
Which approach should the data engineer use?
A platform team lead is responsible for automating SQL Warehouse usage attribution across business units. They need to identify warehouse usage at the individual user level and share a daily usage report with an executive team that includes business leaders from multiple departments.
How should the platform lead generate an automated report that can be shared daily?
A data engineering team needs to implement a tagging system for their tables as part of an automated ETL process, and needs to apply tags programmatically to tables in Unity Catalog.
Which SQL command adds tags to a table programmatically?
The view updates represents an incremental batch of all newly ingested data to be inserted or updated in the customers table.
The following logic is used to process these records.
MERGE INTO customers
USING (
SELECT updates.customer_id as merge_ey, updates .*
FROM updates
UNION ALL
SELECT NULL as merge_key, updates .*
FROM updates JOIN customers
ON updates.customer_id = customers.customer_id
WHERE customers.current = true AND updates.address < > customers.address
) staged_updates
ON customers.customer_id = mergekey
WHEN MATCHED AND customers. current = true AND customers.address < > staged_updates.address THEN
UPDATE SET current = false, end_date = staged_updates.effective_date
WHEN NOT MATCHED THEN
INSERT (customer_id, address, current, effective_date, end_date)
VALUES (staged_updates.customer_id, staged_updates.address, true, staged_updates.effective_date, null)
Which statement describes this implementation?
A production workload incrementally applies updates from an external Change Data Capture feed to a Delta Lake table as an always-on Structured Stream job. When data was initially migrated for this table, OPTIMIZE was executed and most data files were resized to 1 GB. Auto Optimize and Auto Compaction were both turned on for the streaming production job. Recent review of data files shows that most data files are under 64 MB, although each partition in the table contains at least 1 GB of data and the total table size is over 10 TB.
Which of the following likely explains these smaller file sizes?
An upstream source writes Parquet data as hourly batches to directories named with the current date. A nightly batch job runs the following code to ingest all data from the previous day as indicated by the date variable:

Assume that the fields customer_id and order_id serve as a composite key to uniquely identify each order.
If the upstream system is known to occasionally produce duplicate entries for a single order hours apart, which statement is correct?
A streaming video analytics team ingests billions of events daily into a Unity Catalog-managed Delta table video_events . Analysts run ad-hoc point-lookup queries on columns like user_id, campaign_id, and region. The team manually runs OPTIMIZE video_events ZORDER BY (user_id, campaign_id, region), but still sees poor performance on recent data and dislikes the operational overhead. The team wants a hands-off way to keep hot columns co-located as query patterns evolve.
A task orchestrator has been configured to run two hourly tasks. First, an outside system writes Parquet data to a directory mounted at /mnt/raw_orders/. After this data is written, a Databricks job containing the following code is executed:
(spark.readStream
.format( " parquet " )
.load( " /mnt/raw_orders/ " )
.withWatermark( " time " , " 2 hours " )
.dropDuplicates([ " customer_id " , " order_id " ])
.writeStream
.trigger(once=True)
.table( " orders " )
)
Assume that the fields customer_id and order_id serve as a composite key to uniquely identify each order, and that the time field indicates when the record was queued in the source system. If the upstream system is known to occasionally enqueue duplicate entries for a single order hours apart, which statement is correct?
The data engineering team maintains the following code:

Assuming that this code produces logically correct results and the data in the source tables has been de-duplicated and validated, which statement describes what will occur when this code is executed?
Which REST API call can be used to review the notebooks configured to run as tasks in a multi-task job?
Given the following error traceback:
AnalysisException: cannot resolve ' heartrateheartrateheartrate ' given input columns:
[spark_catalog.database.table.device_id, spark_catalog.database.table.heartrate,
spark_catalog.database.table.mrn, spark_catalog.database.table.time]
The code snippet was:
display(df.select(3* " heartrate " ))
Which statement describes the error being raised?
A developer has successfully configured credential for Databricks Repos and cloned a remote Git repository. Hey don not have privileges to make changes to the main branch, which is the only branch currently visible in their workspace.
Use Response to pull changes from the remote Git repository commit and push changes to a branch that appeared as a changes were pulled.
A data engineer is using Lakeflow Declarative Pipelines Expectations feature to track the data quality of their incoming sensor data. Periodically, sensors send bad readings that are out of range, and they are currently flagging those rows with a warning and writing them to the silver table along with the good data. They’ve been given a new requirement – the bad rows need to be quarantined in a separate quarantine table and no longer included in the silver table.
This is the existing code for their silver table:
@dlt.table
@dlt.expect( " valid_sensor_reading " , " reading < 120 " )
def silver_sensor_readings():
return spark.readStream.table( " bronze_sensor_readings " )
What code will satisfy the requirements?
Spill occurs as a result of executing various wide transformations. However, diagnosing spill requires one to proactively look for key indicators.
Where in the Spark UI are two of the primary indicators that a partition is spilling to disk?
A data engineer is designing a Lakeflow Spark Declarative Pipeline to process streaming order data. The pipeline uses Auto Loader to ingest data and must enforce data quality by ensuring customer_id is not null and amount is greater than zero. Invalid records should be dropped. Which Lakeflow Spark Declarative Pipelines configuration implements this requirement using Python?
Which method can be used to determine the total wall-clock time it took to execute a query?
A team of data engineer are adding tables to a DLT pipeline that contain repetitive expectations for many of the same data quality checks.
One member of the team suggests reusing these data quality rules across all tables defined for this pipeline.
What approach would allow them to do this?
A data engineer is designing a pipeline in Databricks that processes records from a Kafka stream where late-arriving data is common.
Which approach should the data engineer use?
The business reporting tem requires that data for their dashboards be updated every hour. The total processing time for the pipeline that extracts transforms and load the data for their pipeline runs in 10 minutes.
Assuming normal operating conditions, which configuration will meet their service-level agreement requirements with the lowest cost?
Although the Databricks Utilities Secrets module provides tools to store sensitive credentials and avoid accidentally displaying them in plain text users should still be careful with which credentials are stored here and which users have access to using these secrets.
Which statement describes a limitation of Databricks Secrets?
The security team is exploring whether or not the Databricks secrets module can be leveraged for connecting to an external database.
After testing the code with all Python variables being defined with strings, they upload the password to the secrets module and configure the correct permissions for the currently active user. They then modify their code to the following (leaving all other variables unchanged).

Which statement describes what will happen when the above code is executed?
A small company based in the United States has recently contracted a consulting firm in India to implement several new data engineering pipelines to power artificial intelligence applications. All the company ' s data is stored in regional cloud storage in the United States.
The workspace administrator at the company is uncertain about where the Databricks workspace used by the contractors should be deployed.
Assuming that all data governance considerations are accounted for, which statement accurately informs this decision?
In order to prevent accidental commits to production data, a senior data engineer has instituted a policy that all development work will reference clones of Delta Lake tables. After testing both deep and shallow clone, development tables are created using shallow clone.
A few weeks after initial table creation, the cloned versions of several tables implemented as Type 1 Slowly Changing Dimension (SCD) stop working. The transaction logs for the source tables show that vacuum was run the day before.
Why are the cloned tables no longer working?
A junior developer complains that the code in their notebook isn ' t producing the correct results in the development environment. A shared screenshot reveals that while they ' re using a notebook versioned with Databricks Repos, they ' re using a personal branch that contains old logic. The desired branch named dev-2.3.9 is not available from the branch selection dropdown.
Which approach will allow this developer to review the current logic for this notebook?
A company has a task management system that tracks the most recent status of tasks. The system takes task events as input and processes events in near real-time using Lakeflow Declarative Pipelines. A new task event is ingested into the system when a task is created or the task status is changed. Lakeflow Declarative Pipelines provides a streaming table (tasks_status) for BI users to query.
The table represents the latest status of all tasks and includes 5 columns:
task_id (unique for each task)
task_name
task_owner
task_status
task_event_time
The table enables three properties: deletion vectors, row tracking, and change data feed (CDF).
A data engineer is asked to create a new Lakeflow Declarative Pipeline to enrich the tasks_status table in near real-time by adding one additional column representing task_owner’s department, which can be looked up from a static dimension table (employee).
How should this enrichment be implemented?
A Data Engineer is building a simple data pipeline using Lakeflow Declarative Pipelines (LDP) in Databricks to ingest customer data. The raw customer data is stored in a cloud storage location in JSON format. The task is to create Lakeflow Declarative Pipelines that read the raw JSON data and write it into a Delta table for further processing.
Which code snippet will correctly ingest the raw JSON data and create a Delta table using LDP?
A data engineering team is migrating off its legacy Hadoop platform. As part of the process, they are evaluating storage formats for performance comparison. The legacy platform uses ORC and RCFile formats. After converting a subset of data to Delta Lake , they noticed significantly better query performance. Upon investigation, they discovered that queries reading from Delta tables leveraged a Shuffle Hash Join , whereas queries on legacy formats used Sort Merge Joins . The queries reading Delta Lake data also scanned less data.
Which reason could be attributed to the difference in query performance?
A data engineer is designing a Lakeflow Declarative Pipeline to process streaming order data. The pipeline uses Auto Loader to ingest data and must enforce data quality by ensuring customer_id and amount are greater than zero. Invalid records should be dropped.
Which Lakeflow Declarative Pipelines configurations implement this requirement using Python?
The data science team has requested assistance in accelerating queries on free form text from user reviews. The data is currently stored in Parquet with the below schema:
item_id INT, user_id INT, review_id INT, rating FLOAT, review STRING
The review column contains the full text of the review left by the user. Specifically, the data science team is looking to identify if any of 30 key words exist in this field.
A junior data engineer suggests converting this data to Delta Lake will improve query performance.
Which response to the junior data engineer s suggestion is correct?
The data governance team is reviewing code used for deleting records for compliance with GDPR. They note the following logic is used to delete records from the Delta Lake table named users .

Assuming that user_id is a unique identifying key and that delete_requests contains all users that have requested deletion, which statement describes whether successfully executing the above logic guarantees that the records to be deleted are no longer accessible and why?
A data engineer has a Delta table orders with deletion vectors enabled. The engineer executes the following command:
DELETE FROM orders WHERE status = ' cancelled ' ;
What should be the behavior of deletion vectors when the command is executed?
The Databricks CLI is use to trigger a run of an existing job by passing the job_id parameter. The response that the job run request has been submitted successfully includes a filed run_id.
Which statement describes what the number alongside this field represents?
A data engineer, while designing a Pandas UDF to process financial time-series data with complex calculations that require maintaining state across rows within each stock symbol group, must ensure the function is efficient and scalable.
Which approach will solve the problem with minimum overhead while preserving data integrity?
An analytics team wants to run a short-term experiment in Databricks SQL on the customer transactions Delta table (about 20 billion records) created by the data engineering team. Which strategy should the data engineering team use to ensure minimal downtime and no impact on the ongoing ETL processes?
A production cluster has 3 executor nodes and uses the same virtual machine type for the driver and executor.
When evaluating the Ganglia Metrics for this cluster, which indicator would signal a bottleneck caused by code executing on the driver?
Review the following error traceback:

Which statement describes the error being raised?
A table is registered with the following code:
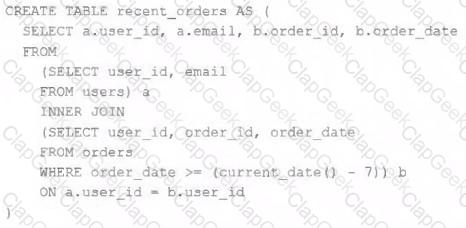
Both users and orders are Delta Lake tables. Which statement describes the results of querying recent_orders ?
A data engineer is building a Lakeflow Declarative Pipelines pipeline to process healthcare claims data. A metadata JSON file defines data quality rules for multiple tables, including:
{
" claims " : [
{ " name " : " valid_patient_id " , " constraint " : " patient_id IS NOT NULL " },
{ " name " : " non_negative_amount " , " constraint " : " claim_amount > = 0 " }
]
}
The pipeline must dynamically apply these rules to the claims table without hardcoding the rules.
How should the data engineer achieve this?
The following code has been migrated to a Databricks notebook from a legacy workload:

The code executes successfully and provides the logically correct results, however, it takes over 20 minutes to extract and load around 1 GB of data.
Which statement is a possible explanation for this behavior?
The data engineering team is migrating an enterprise system with thousands of tables and views into the Lakehouse. They plan to implement the target architecture using a series of bronze, silver, and gold tables. Bronze tables will almost exclusively be used by production data engineering workloads, while silver tables will be used to support both data engineering and machine learning workloads. Gold tables will largely serve business intelligence and reporting purposes. While personal identifying information (PII) exists in all tiers of data, pseudonymization and anonymization rules are in place for all data at the silver and gold levels.
The organization is interested in reducing security concerns while maximizing the ability to collaborate across diverse teams.
Which statement exemplifies best practices for implementing this system?
The data science team has created and logged a production using MLFlow. The model accepts a list of column names and returns a new column of type DOUBLE.
The following code correctly imports the production model, load the customer table containing the customer_id key column into a Dataframe, and defines the feature columns needed for the model.

Which code block will output DataFrame with the schema ' ' customer_id LONG, predictions DOUBLE ' ' ?
A data engineering team uses Databricks Lakehouse Monitoring to track the percent_null metric for a critical column in their Delta table.
The profile metrics table (prod_catalog.prod_schema.customer_data_profile_metrics) stores hourly percent_null values.
The team wants to:
Trigger an alert when the daily average of percent_null exceeds 5% for three consecutive days .
Ensure that notifications are not spammed during sustained issues.
Options:
The data engineer is using Spark ' s MEMORY_ONLY storage level.
Which indicators should the data engineer look for in the spark UI ' s Storage tab to signal that a cached table is not performing optimally?
A junior data engineer is migrating a workload from a relational database system to the Databricks Lakehouse. The source system uses a star schema, leveraging foreign key constrains and multi-table inserts to validate records on write.
Which consideration will impact the decisions made by the engineer while migrating this workload?
A data engineer is configuring a Databricks Asset Bundle to deploy a job with granular permissions. The requirements are:
• Grant the data-engineers group CAN_MANAGE access to the job.
• Ensure the auditors’ group can view the job but not modify/run it.
• Avoid granting unintended permissions to other users/groups.
How should the data engineer deploy the job while meeting the requirements?
A data governance team at a large enterprise is improving data discoverability across its organization. The team has hundreds of tables in their Databricks Lakehouse with thousands of columns that lack proper documentation. Many of these tables were created by different teams over several years, with missing context about column meanings and business logic. The data governance team needs to quickly generate comprehensive column descriptions for all existing tables to meet compliance requirements and improve data literacy across the organization. They want to leverage modern capabilities to automatically generate meaningful descriptions rather than manually documenting each column, which would take months to complete.
Which approach should the team use in Databricks to automatically generate column comments and descriptions for existing tables?
An upstream system is emitting change data capture (CDC) logs that are being written to a cloud object storage directory. Each record in the log indicates the change type (insert, update, or delete) and the values for each field after the change. The source table has a primary key identified by the field pk_id .
For auditing purposes, the data governance team wishes to maintain a full record of all values that have ever been valid in the source system. For analytical purposes, only the most recent value for each record needs to be recorded. The Databricks job to ingest these records occurs once per hour, but each individual record may have changed multiple times over the course of an hour.
Which solution meets these requirements?
A Databricks job has been configured with 3 tasks, each of which is a Databricks notebook. Task A does not depend on other tasks. Tasks B and C run in parallel, with each having a serial dependency on Task A.
If task A fails during a scheduled run, which statement describes the results of this run?
A Delta Lake table representing metadata about content from user has the following schema:
user_id LONG, post_text STRING, post_id STRING, longitude FLOAT, latitude FLOAT, post_time TIMESTAMP, date DATE
Based on the above schema, which column is a good candidate for partitioning the Delta Table?
A workspace admin has created a new catalog called finance_data and wants to delegate permission management to a finance team lead without giving them full admin rights.
Which privilege should be granted to the finance team lead?




TESTED 20 Jun 2026