4 of 55.
A developer is working on a Spark application that processes a large dataset using SQL queries. Despite having a large cluster, the developer notices that the job is underutilizing the available resources. Executors remain idle for most of the time, and logs reveal that the number of tasks per stage is very low. The developer suspects that this is causing suboptimal cluster performance.
Which action should the developer take to improve cluster utilization?
35 of 55.
A data engineer is building a Structured Streaming pipeline and wants it to recover from failures or intentional shutdowns by continuing where it left off.
How can this be achieved?
A data engineer wants to process a streaming DataFrame that receives sensor readings every second with columns sensor_id, temperature, and timestamp. The engineer needs to calculate the average temperature for each sensor over the last 5 minutes while the data is streaming.
Which code implementation achieves the requirement?
Options from the images provided:
A)
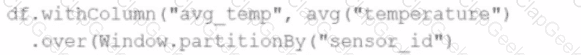
B)

C)
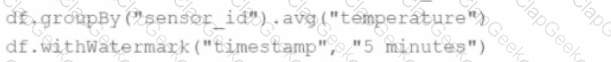
D)

29 of 55.
A Spark application is experiencing performance issues in client mode due to the driver being resource-constrained.
How should this issue be resolved?
A data engineer observes that an upstream streaming source sends duplicate records, where duplicates share the same key and have at most a 30-minute difference in event_timestamp. The engineer adds:
dropDuplicatesWithinWatermark("event_timestamp", "30 minutes")
What is the result?
17 of 55.
A data engineer has noticed that upgrading the Spark version in their applications from Spark 3.0 to Spark 3.5 has improved the runtime of some scheduled Spark applications.
Looking further, the data engineer realizes that Adaptive Query Execution (AQE) is now enabled.
Which operation should AQE be implementing to automatically improve the Spark application performance?
A data engineer noticed improved performance after upgrading from Spark 3.0 to Spark 3.5. The engineer found that Adaptive Query Execution (AQE) was enabled.
Which operation is AQE implementing to improve performance?
A Spark engineer must select an appropriate deployment mode for the Spark jobs.
What is the benefit of using cluster mode in Apache Spark™?
15 of 55.
A data engineer is working on a Streaming DataFrame (streaming_df) with the following streaming data:
id
name
count
timestamp
1
Delhi
20
2024-09-19T10:11
1
Delhi
50
2024-09-19T10:12
2
London
50
2024-09-19T10:15
3
Paris
30
2024-09-19T10:18
3
Paris
20
2024-09-19T10:20
4
Washington
10
2024-09-19T10:22
Which operation is supported with streaming_df?
40 of 55.
A developer wants to refactor older Spark code to take advantage of built-in functions introduced in Spark 3.5.
The original code:
from pyspark.sql import functions as F
min_price = 110.50
result_df = prices_df.filter(F.col("price") > min_price).agg(F.count("*"))
Which code block should the developer use to refactor the code?
41 of 55.
A data engineer is working on the DataFrame df1 and wants the Name with the highest count to appear first (descending order by count), followed by the next highest, and so on.
The DataFrame has columns:
id | Name | count | timestamp
---------------------------------
1 | USA | 10
2 | India | 20
3 | England | 50
4 | India | 50
5 | France | 20
6 | India | 10
7 | USA | 30
8 | USA | 40
Which code fragment should the engineer use to sort the data in the Name and count columns?
A data engineer wants to write a Spark job that creates a new managed table. If the table already exists, the job should fail and not modify anything.
Which save mode and method should be used?
44 of 55.
A data engineer is working on a real-time analytics pipeline using Spark Structured Streaming.
They want the system to process incoming data in micro-batches at a fixed interval of 5 seconds.
Which code snippet fulfills this requirement?
A data engineer is running a batch processing job on a Spark cluster with the following configuration:
10 worker nodes
16 CPU cores per worker node
64 GB RAM per node
The data engineer wants to allocate four executors per node, each executor using four cores.
What is the total number of CPU cores used by the application?
A data scientist is working on a large dataset in Apache Spark using PySpark. The data scientist has a DataFrame df with columns user_id, product_id, and purchase_amount and needs to perform some operations on this data efficiently.
Which sequence of operations results in transformations that require a shuffle followed by transformations that do not?
A developer wants to test Spark Connect with an existing Spark application.
What are the two alternative ways the developer can start a local Spark Connect server without changing their existing application code? (Choose 2 answers)
Which feature of Spark Connect is considered when designing an application to enable remote interaction with the Spark cluster?
Given the following code snippet in my_spark_app.py:

What is the role of the driver node?
A data engineer wants to create a Streaming DataFrame that reads from a Kafka topic called feed.

Which code fragment should be inserted in line 5 to meet the requirement?
Code context:
spark \
.readStream \
.format("kafka") \
.option("kafka.bootstrap.servers", "host1:port1,host2:port2") \
.[LINE 5] \
.load()
Options:
A Spark developer is building an app to monitor task performance. They need to track the maximum task processing time per worker node and consolidate it on the driver for analysis.
Which technique should be used?
A Spark application developer wants to identify which operations cause shuffling, leading to a new stage in the Spark execution plan.
Which operation results in a shuffle and a new stage?
In the code block below, aggDF contains aggregations on a streaming DataFrame:

Which output mode at line 3 ensures that the entire result table is written to the console during each trigger execution?
A data analyst builds a Spark application to analyze finance data and performs the following operations: filter, select, groupBy, and coalesce.
Which operation results in a shuffle?
A data scientist at a financial services company is working with a Spark DataFrame containing transaction records. The DataFrame has millions of rows and includes columns for transaction_id, account_number, transaction_amount, and timestamp. Due to an issue with the source system, some transactions were accidentally recorded multiple times with identical information across all fields. The data scientist needs to remove rows with duplicates across all fields to ensure accurate financial reporting.
Which approach should the data scientist use to deduplicate the orders using PySpark?
13 of 55.
A developer needs to produce a Python dictionary using data stored in a small Parquet table, which looks like this:
region_id
region_name
10
North
12
East
14
West
The resulting Python dictionary must contain a mapping of region_id to region_name, containing the smallest 3 region_id values.
Which code fragment meets the requirements?
34 of 55.
A data engineer is investigating a Spark cluster that is experiencing underutilization during scheduled batch jobs.
After checking the Spark logs, they noticed that tasks are often getting killed due to timeout errors, and there are several warnings about insufficient resources in the logs.
Which action should the engineer take to resolve the underutilization issue?
A data analyst wants to add a column date derived from a timestamp column.
Options:
What is the risk associated with this operation when converting a large Pandas API on Spark DataFrame back to a Pandas DataFrame?
A data scientist is working on a project that requires processing large amounts of structured data, performing SQL queries, and applying machine learning algorithms. The data scientist is considering using Apache Spark for this task.
Which combination of Apache Spark modules should the data scientist use in this scenario?
Options:
A developer is running Spark SQL queries and notices underutilization of resources. Executors are idle, and the number of tasks per stage is low.
What should the developer do to improve cluster utilization?
32 of 55.
A developer is creating a Spark application that performs multiple DataFrame transformations and actions. The developer wants to maintain optimal performance by properly managing the SparkSession.
How should the developer handle the SparkSession throughout the application?
An engineer has two DataFrames: df1 (small) and df2 (large). A broadcast join is used:
python
CopyEdit
from pyspark.sql.functions import broadcast
result = df2.join(broadcast(df1), on='id', how='inner')
What is the purpose of using broadcast() in this scenario?
Options:
36 of 55.
What is the main advantage of partitioning the data when persisting tables?
A data engineer is working on the DataFrame:
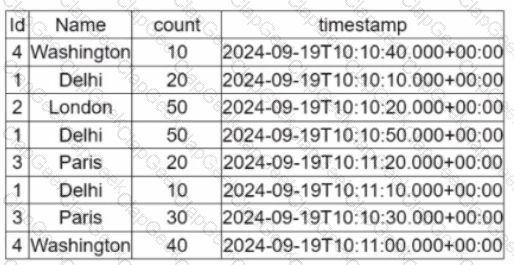
(Referring to the table image: it has columns Id, Name, count, and timestamp.)
Which code fragment should the engineer use to extract the unique values in the Name column into an alphabetically ordered list?
Given a CSV file with the content:

And the following code:
from pyspark.sql.types import *
schema = StructType([
StructField("name", StringType()),
StructField("age", IntegerType())
])
spark.read.schema(schema).csv(path).collect()
What is the resulting output?
A Spark engineer is troubleshooting a Spark application that has been encountering out-of-memory errors during execution. By reviewing the Spark driver logs, the engineer notices multiple "GC overhead limit exceeded" messages.
Which action should the engineer take to resolve this issue?
25 of 55.
A Data Analyst is working on employees_df and needs to add a new column where a 10% tax is calculated on the salary.
Additionally, the DataFrame contains the column age, which is not needed.
Which code fragment adds the tax column and removes the age column?




TESTED 20 Jul 2026