The code block displayed below contains an error. The code block should configure Spark to split data in 20 parts when exchanging data between executors for joins or aggregations. Find the error.
Code block:
spark.conf.set(spark.sql.shuffle.partitions, 20)
Which of the following describes the conversion of a computational query into an execution plan in Spark?
The code block shown below should return a DataFrame with two columns, itemId and col. In this DataFrame, for each element in column attributes of DataFrame itemDf there should be a separate
row in which the column itemId contains the associated itemId from DataFrame itemsDf. The new DataFrame should only contain rows for rows in DataFrame itemsDf in which the column attributes
contains the element cozy.
A sample of DataFrame itemsDf is below.
Code block:
itemsDf.__1__(__2__).__3__(__4__, __5__(__6__))
Which of the following statements about the differences between actions and transformations is correct?
Which of the following code blocks reads JSON file imports.json into a DataFrame?
Which of the following describes the difference between client and cluster execution modes?
Which of the following code blocks returns a DataFrame where columns predError and productId are removed from DataFrame transactionsDf?
Sample of DataFrame transactionsDf:
1.+-------------+---------+-----+-------+---------+----+
2.|transactionId|predError|value|storeId|productId|f |
3.+-------------+---------+-----+-------+---------+----+
4.|1 |3 |4 |25 |1 |null|
5.|2 |6 |7 |2 |2 |null|
6.|3 |3 |null |25 |3 |null|
7.+-------------+---------+-----+-------+---------+----+
The code block shown below should show information about the data type that column storeId of DataFrame transactionsDf contains. Choose the answer that correctly fills the blanks in the code
block to accomplish this.
Code block:
transactionsDf.__1__(__2__).__3__
The code block displayed below contains an error. The code block should combine data from DataFrames itemsDf and transactionsDf, showing all rows of DataFrame itemsDf that have a matching
value in column itemId with a value in column transactionsId of DataFrame transactionsDf. Find the error.
Code block:
itemsDf.join(itemsDf.itemId==transactionsDf.transactionId)
The code block shown below should return a two-column DataFrame with columns transactionId and supplier, with combined information from DataFrames itemsDf and transactionsDf. The code
block should merge rows in which column productId of DataFrame transactionsDf matches the value of column itemId in DataFrame itemsDf, but only where column storeId of DataFrame
transactionsDf does not match column itemId of DataFrame itemsDf. Choose the answer that correctly fills the blanks in the code block to accomplish this.
Code block:
transactionsDf.__1__(itemsDf, __2__).__3__(__4__)
Which of the following code blocks immediately removes the previously cached DataFrame transactionsDf from memory and disk?
Which of the following code blocks returns a new DataFrame with only columns predError and values of every second row of DataFrame transactionsDf?
Entire DataFrame transactionsDf:
1.+-------------+---------+-----+-------+---------+----+
2.|transactionId|predError|value|storeId|productId| f|
3.+-------------+---------+-----+-------+---------+----+
4.| 1| 3| 4| 25| 1|null|
5.| 2| 6| 7| 2| 2|null|
6.| 3| 3| null| 25| 3|null|
7.| 4| null| null| 3| 2|null|
8.| 5| null| null| null| 2|null|
9.| 6| 3| 2| 25| 2|null|
10.+-------------+---------+-----+-------+---------+----+
Which of the following code blocks returns a copy of DataFrame transactionsDf that only includes columns transactionId, storeId, productId and f?
Sample of DataFrame transactionsDf:
1.+-------------+---------+-----+-------+---------+----+
2.|transactionId|predError|value|storeId|productId| f|
3.+-------------+---------+-----+-------+---------+----+
4.| 1| 3| 4| 25| 1|null|
5.| 2| 6| 7| 2| 2|null|
6.| 3| 3| null| 25| 3|null|
7.+-------------+---------+-----+-------+---------+----+
The code block shown below should return the number of columns in the CSV file stored at location filePath. From the CSV file, only lines should be read that do not start with a # character. Choose
the answer that correctly fills the blanks in the code block to accomplish this.
Code block:
__1__(__2__.__3__.csv(filePath, __4__).__5__)
Which of the following code blocks returns a copy of DataFrame transactionsDf where the column storeId has been converted to string type?
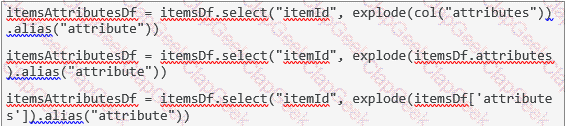
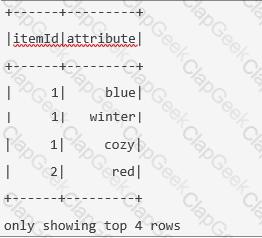
The code block displayed below contains an error. The code block should create DataFrame itemsAttributesDf which has columns itemId and attribute and lists every attribute from the attributes column in DataFrame itemsDf next to the itemId of the respective row in itemsDf. Find the error.
A sample of DataFrame itemsDf is below.

Code block:
itemsAttributesDf = itemsDf.explode("attributes").alias("attribute").select("attribute", "itemId")
The code block displayed below contains an error. The code block should arrange the rows of DataFrame transactionsDf using information from two columns in an ordered fashion, arranging first by
column value, showing smaller numbers at the top and greater numbers at the bottom, and then by column predError, for which all values should be arranged in the inverse way of the order of items
in column value. Find the error.
Code block:
transactionsDf.orderBy('value', asc_nulls_first(col('predError')))
Which of the following code blocks returns a DataFrame that has all columns of DataFrame transactionsDf and an additional column predErrorSquared which is the squared value of column
predError in DataFrame transactionsDf?
Which of the following code blocks returns about 150 randomly selected rows from the 1000-row DataFrame transactionsDf, assuming that any row can appear more than once in the returned
DataFrame?




TESTED 01 Aug 2026

 C:\Users\Admin\Desktop\Data\Odt data\Untitled.jpg
C:\Users\Admin\Desktop\Data\Odt data\Untitled.jpg