You have an Azure Databricks workspace that contains a job in Lakeflow Jobs named Job1. Job1 contains multiple tasks.
Failures of non-critical tasks must be logged but must NOT trigger notifications. Notifications must be triggered only when critical tasks have failed, and Job1 has completed
You need to configure the job alerting behavior.
What should trigger a notification?
You have an Azure Databricks workspace that is enabled for Unity Catalog and contains two managed Delta tables named sales.schema1.table1 and sales.schema1.table2.
sales.schema1.table1 contains sales data from the current year.
sales.schema1.table2 contains historical data.
You need to load all the rows from sales.schema1.table1 into sales.schema1.table2. The solution must preserve any existing data in sales.schema1.table2 and minimize processing effort.
Which command should you run?
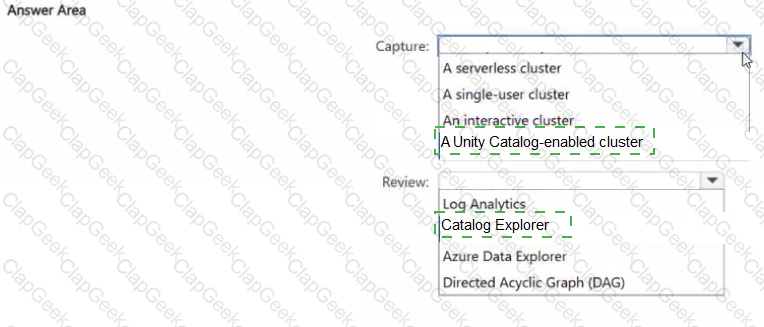
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You need to ensure that data lineage is captured and can be reviewed for tables accessed by Databricks notebooks and jobs. The solution must minimize administrative effort.
Which compute configuration should you use to capture the data lineage, and what should you use to review the data lineage? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.

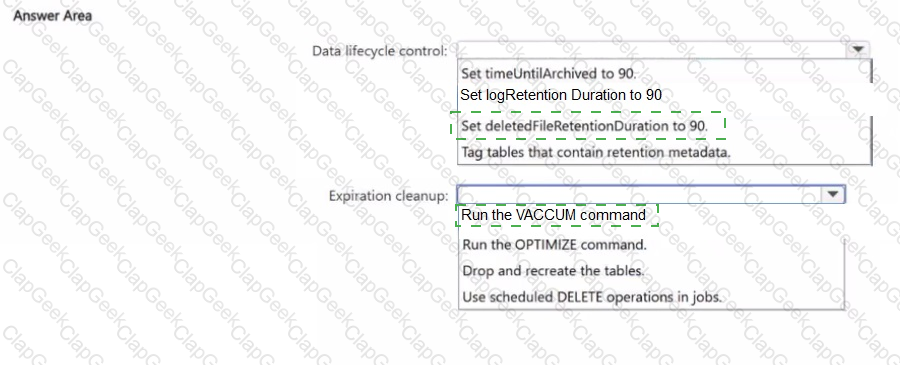
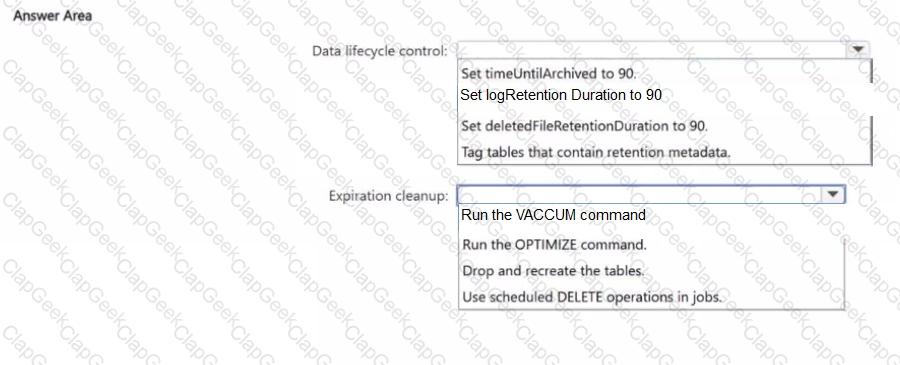
You have an Azure Databricks workspace that is enabled for Unity Catalog.
You need to implement a data lifecycle and expiration solution that meets the following requirements
• Transaction logs and deleted data files that are older than 90 days must be removed from Delta tables to reclaim storage.
• All the tables must remain available for querying during the cleanup process.
• Administrative effort must be minimized
What should you do for each requirement? To answer, select the appropriate options in the answer area.
NOTE: Each correct selection is worth one point.
You need to configure compute for the ingestion of telemetry data. The solution must meet the data ingestion and processing requirements.
What should you do?
You need to develop the task logic for a new job in Lakeflow Jobs that processes telemetry data.
Each task must contain only the appropriate logic for its step in the pipeline. The solution must support the planned changes and meet the data ingestion and processing requirements.
What should you do?




TESTED 20 Jun 2026